R19: Bayesian Risk Modeling of U.S. Supply Chains in North America (Mexico-U.S.-Canada): From the Integration of Case Studies to the Formulation of a Best Practices Guideline
To assess and manage the State of Risk of any given U.S. supply chain extending across North America (Mexico-U.S.-Canada) it is required to account for its complexity and for all evidence available to characterize it. This is possible by fully documenting each supply chain’s operation and all likely natural and anthropogenic threats which the supply chain’s system components are exposed to, and all social, economic and environmental impacts produced during its operation.
Supply Chains
Click on each supply chain to learn more.
R18: Risk Taskforce for North America: Data-Lake System and Data-Management Workflow to Support Decision-Making of Supply Chains Across the United States, Mexico and Canada
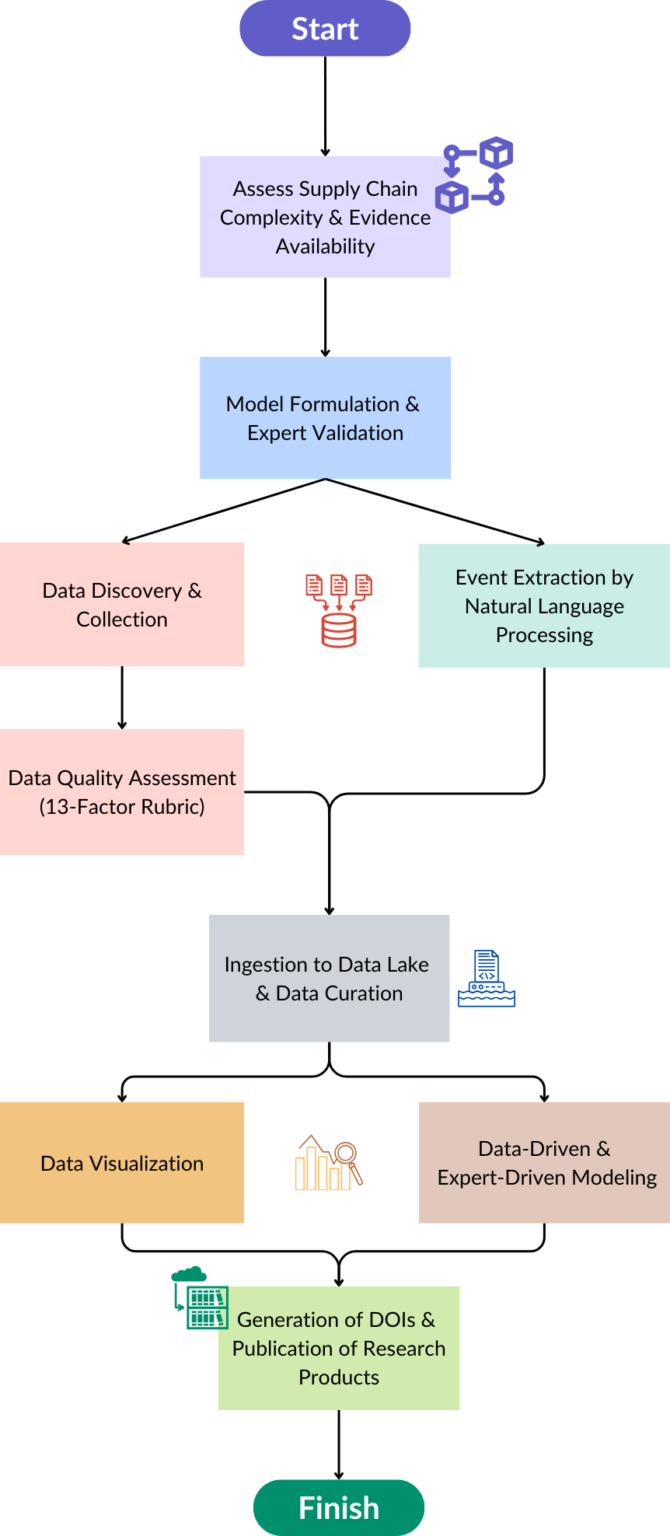
To assess and manage the State of Risk of any given U.S. supply chain extending across North America (MEX-USA-CAN), it is required to account for its complexity (i.e. through a Bayesian risk model) and for all evidence available to characterize it (i.e. data from observations, data from model predictions, and data from experts’ knowledge). This is possible by the integration of a Data-Lake System (CBTS-DLS) coupled with a Data-Management Workflow (CBTS-DMWF), supporting the development of a set of supply chain Case Studies (strategically defined to account for supply chain’s varying degrees of complexity and varying evidence availability), where each, includes the formulation and validation of a Risk Minimum Viable Model (i.e. a Bayesian RMVM), and its corresponding calibration and testing.
Data Management Workflow
Establishing a process where interdisciplinary Teams can conduct supply chain risk assessment and management.
Data Lake System Infrastructure
Learn about the elements of the hybrid server infrastructure by clicking on the icons in the image.
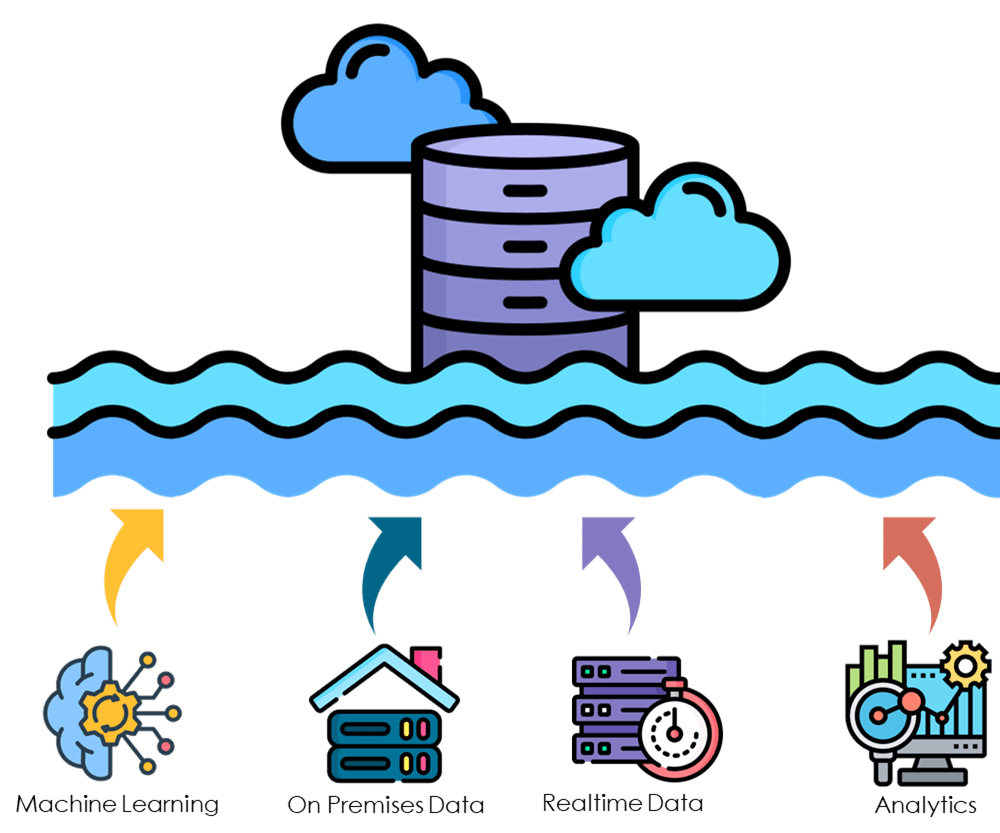
Results are pushed to the cloud for access
to the general public via a dashboard.
Data-driven models where AI can produce a forward model
following a machine learning regression formulation,
based on the same data as Bayesian Network expert-driven models .
The on-premises infrastructure
includes CPUs for processing and storage,
and GPUs for probabilistic risk assessment computing.
Data stored in the data lake system infrastructure
can be accessed real-time.
Structured and unstructured can be stored,
providing high flexibility for
different types of analysis.
